APIで取得したChEMBLのデータを整える(2)
前回紹介した方法はほぼほぼコピペでした。
.only() で取得する項目を限定していましたが、全データを取得しようとするとどうなるでしょう?
activities = new_client.activity.filter(
target_chembl_id__in='CHEMBL3553',
pchembl_value__gte=5,
assay_type='B',
)
pd.DataFrame(activities).columns
Index(['activity_comment', 'activity_id', 'activity_properties',
'assay_chembl_id', 'assay_description', 'assay_type',
'assay_variant_accession', 'assay_variant_mutation', 'bao_endpoint',
'bao_format', 'bao_label', 'canonical_smiles', 'data_validity_comment',
'data_validity_description', 'document_chembl_id', 'document_journal',
'document_year', 'ligand_efficiency', 'molecule_chembl_id',
'molecule_pref_name', 'parent_molecule_chembl_id', 'pchembl_value',
'potential_duplicate', 'qudt_units', 'record_id', 'relation', 'src_id',
'standard_flag', 'standard_relation', 'standard_text_value',
'standard_type', 'standard_units', 'standard_upper_value',
'standard_value', 'target_chembl_id', 'target_organism',
'target_pref_name', 'target_tax_id', 'text_value', 'toid', 'type',
'units', 'uo_units', 'upper_value', 'value'],
dtype='object')
いっぱいカラムありますよね。残念ながらAlogPとかがないことがわかります。
ligand_efficiency はLEかな?
pd.DataFrame(activities).loc[:4, ['ligand_efficiency']]
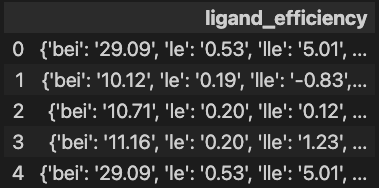
え?valueじゃなくてdictなの?
っていうことでこのままではplotや計算に使うことが出来ませんでした。What a fxxk !!
と、いう訳でpd.DataFrame()ではなくpd.json_normalize()をつかってネスト(入れ子)になったdictを各カラムに分解してやります。
df = pd.json_normalize(activities) df.iloc[:4, -4:]

というわけで無事にAPIでDLしたデータを解析できる状態に出来ました。
扱ってみた印象だけならAPIよりcsvでDLした方が軽くて扱いやすい気がしました。
次回へ続く。